
 由
Anna-Search
发布于
2025年06月28日
由
Anna-Search
发布于
2025年06月28日
基于LLM的OSINT代理,具有记忆、知识集成、工具应用和自我反思

Zhijie Shen
清华大学计算机科学与技术系,北京,中国
shenzj24@mails.tsinghua.edu.cn
Qian Wu
清华大学自动化部,北京,中国
q-wu24@mails.tsinghua.edu.cn
Keyu Shen
清华大学精密仪器系,北京,中国
sky24@mails.tsinghua.edu .cn
摘要
本文介绍了一种基于语言模型(LLM)的开源情报(OSINT)代理系统,旨在应对多源、动态情报周期带来的持续挑战。该系统集成了记忆模块、领域特定知识先验、自动化工具和自我反思机制,以实现高效的数据收集、处理和分析。其核心功能包括检索增强生成(RAG),支持专门指令的生成,以及基于Neo4j的知识图谱,有助于结构化数据表示和精确查询执行。为了评估系统的性能,我们设计并实施了涵盖人员画像、组织结构提取、事件摘要和实体关系映射等多样任务的评估。实验结果显示,该系统在人员画像方面达到了82%的准确率,在事件摘要方面达到了95%的准确率。然而,研究也指出了几个局限性,如多模态数据整合不足、管理冲突信息的难度以及因果推理能力有限。因此,未来的研究将重点放在引入先进的自学习机制、强大的事实核查模块和增强的多模态处理框架上,最终目标是在复杂多变的真实世界场景中实现更有效且更具韧性的OSINT应用。
1.导言
全球商业环境日益复杂且变化迅速,这要求智能系统能够提供及时、准确且具有实际操作价值的洞察,以应对多样化和动态的市场。传统的市场情报收集方法,如使馆咨询、贸易展览和人工调查,长期以来一直是国际商业策略的基础工具。然而,这些方法正受到静态数据源、分散的工作流程、缓慢的信息检索速度以及高昂运营成本的限制。随着全球市场的不断演变,这些局限性阻碍了它们跟上现代商业动态的步伐,尤其是在多组织和跨国合作的背景下。
为了解决这些低效问题,开源情报(OSINT)作为一种关键的替代方案应运而生。OSINT系统能够从公开的数据源,如网络内容、社交媒体和其他开放数据集,实现大规模、高效的收集和分析信息,显著提升了情报周期的效率[1]。与传统方法相比,OSINT提供了更广泛的覆盖范围、更高的操作速度和更低的成本,使得机器学习技术在现代商业环境中越来越重要。支持向量机和随机森林等机器学习技术,以及卷积神经网络(CNN)和长短期记忆(LSTM)神经网络等人工神经网络,推动了AI驱动的OSINT方法的发展,这些技术不仅提高了性能和效率,还减少了人力需求。
尽管当前的OSINT工具具有诸多优势,但它们仍面临显著挑战,包括数据量庞大且变化多端,以及需要及时、情境敏感的分析。虽然AI驱动的方法带来了显著的进步,但仍存在明显局限。这些方法往往严重依赖单一来源的数据,尤其是Twitter,这削弱了它们的稳健性和普遍适用性。此外,这些方法未能有效融入整个情报周期,特别是在信息传播阶段,需要对洞察进行分析、情境化处理,并及时传达给相关方[2]。因此,现有的解决方案往往无法提供解决全球企业复杂需求所需的实时、高精度情报。
为应对这些挑战,我们推出了一款OSINT代理,该代理将前沿的人工智能技术与针对海外营销场景定制的特定工具和能力相结合。系统的核心是大型语言模型(LLM),利用其先进的自然语言理解和生成能力处理大量非结构化数据。在此基础上,代理动态地整合了记忆模块,以保留和回忆上下文信息,从而实现更一致、更有洞察力的分析。通过构建和维护实时动态知识图谱,系统能够映射实体、事件和新兴趋势之间的关系,为企业提供全球市场的全面视角。为了确保广泛的数据覆盖并减少对单一信息源的依赖,OSINT代理集成了多种开源情报工具,从网站、社交媒体平台、新闻机构和其他公开数据库中聚合多样化的数据流。此外,系统还采用了自我反思反馈循环,通过迭代自我评估和优化输出,确保其准确性和相关性,并适应不断变化的市场需求。
我们的集成设计旨在克服现有基于AI的OSINT方法的局限,提供一种可扩展、实时的解决方案,能够以显著降低的操作成本提供高保真情报。我们的智能OSINT对话代理适用于个人、组织、事件和领域的分析。该代理能够维护动态的领域知识图谱,并生成如国家报告等情报输出。通过填补情报周期中的空白并有效整合多源数据,OSINT代理使海外企业能够以前所未有的速度和精度监控全球市场,识别新兴趋势,并提取可操作的见解。
2.相关工作
2.1 开源情报(OSINT)
一般定义:OSINT被定义为从“开放来源,包括互联网、传统大众媒体、专业期刊、会议记录、智库研究、照片、地图和商业影像产品”中收集信息。[3]
传统OSINT方法和工具:从数据收集到处理和分析,常见的OSINT工具包括Spiderfoot[4]、Maltego[5]和Sublist3r[6]。例如,Spiderfoot能够自动查询公共数据源,收集关于IP地址、域名、名称和电子邮件的情报。它还能扫描网站,查找SQL注入和跨站脚本(XSS)等漏洞,使其成为强大的侦察工具。Maltego则侧重于深度数据分析,并通过基于图的可视化技术,直观地展示实体间的关系,便于探索这些联系。值得注意的是,目前大多数这些工具尚未与前沿的人工智能技术集成[2]。
基于人工智能的OSINT方法:在OSINT任务中,结合了多种人工智能技术的新方法已被采用。这些方法主要利用了机器学习技术,包括支持向量机(SVM)、朴素贝叶斯、随机森林,以及卷积神经网络(CNN)和长短期记忆(LSTM)等神经网络。如图1所示。支持向量机(SVM)常用于文本分类,例如通过TF-IDF等特征检测假新闻[7]。卷积神经网络(CNN)在图像分类任务中表现出色,例如PicHunt系统,该系统分析社交媒体图片以供执法使用[8]。结合CNN和长短期记忆网络(LSTM)的混合模型也显示出有效性,例如在恶意域名检测[9]和域名分类[10]方面。较少见的方法包括用于情感分析预处理的LASSO回归[11]和用于网络攻击预测的注释概率时间逻辑(APT)[12]。大多数现有研究集中在情报周期的处理和分析阶段,而规划和评估阶段则较少被探讨[13]。
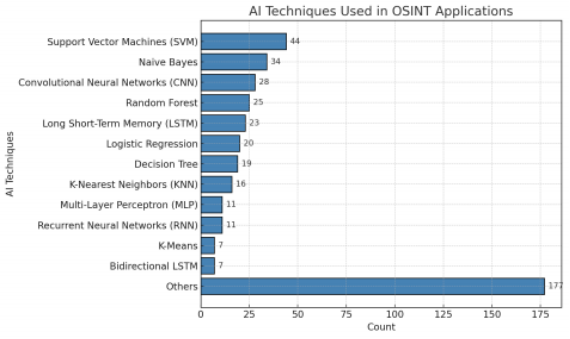
图1:OSINT应用中采用的人工智能技术。数据来源于Browne等人的研究[2]
2.2 LLM代理
大型语言模型(LLMs),例如GPT-4,已经展现出从非结构化和多模态数据中提取洞察力的显著能力。通过整合领域特定知识,检索增强生成(RAG)等技术进一步提升了这些模型的性能,使得输出更加精确且具有上下文意识。因此,基于LLM的AI代理正在通用和特定领域的应用中崭露头角[14]。然而,基于LLM的代理在OSINT(操作系统情报)中的应用仍处于初级阶段,对准确性和效率、适应性以及领域专业知识的需求尤为迫切。目前的实现往往在与自动化工作流程、实时数据收集管道和迭代优化机制的整合上存在局限。这些不足之处凸显了开发一个统一框架的巨大潜力,该框架能够结合LLM的适应性和特定领域的智能工具,解决OSINT的独特挑战,并在实际应用中实现更高效、实时的决策。
Langchain:我们提出的OSINT LLM代理的实现得益于LangChain [15],这是一个专门为与大型语言模型(如GPT)交互而设计的开源框架。Langchain通过支持操作链式处理和智能代理的创建,提供了一种灵活且模块化的自然语言任务处理方法。它能够无缝集成大型语言模型与外部工具、API及数据源,增强了系统执行复杂工作流程的能力,例如多步骤推理、数据提取和决策制定。这种架构显著提升了系统的智能性和适应性,使其非常适合需要实时信息处理和知识综合动态OSINT任务。
3.方法
以LLM代理为核心,我们致力于构建一个全面的OSINT解决方案框架,涵盖前端可视化、后端处理以及数据的收集、处理和存储,确保系统的高效性和可扩展性。总体概念图见图2。在本节中,我们将避免过多解释已知的技术细节,而是重点介绍三个关键子系统:数据收集、知识图谱与动态查询机制,以及基于LLM的交互式OSINT代理。
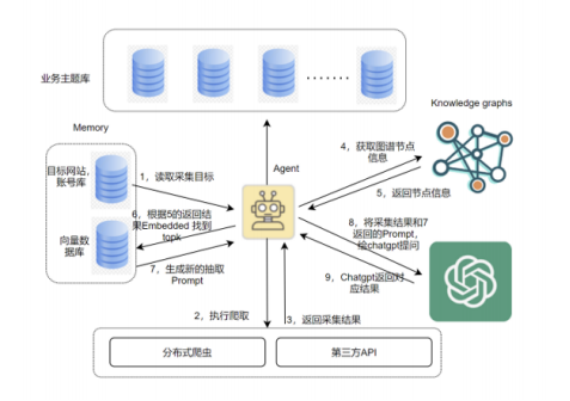
图2:总体概念图
3.1 数据采集处理子系统
由于大型语言模型(LLM)的性能很大程度上取决于输入数据的质量和上下文相关性,因此数据收集与处理子系统的主要任务是从社交媒体、新闻网站、论坛和暗网等不同来源提取相关数据,并进行全面的预处理,确保LLM接收到的数据是干净、结构化或半结构化的。子系统的结构如图3所示。
更具体地说,数据收集和处理子系统采用了先进的爬虫技术,包括用于结构化爬取任务的Scrapy、用于与动态内容自动交互的Selenium和UIAutomator2,以及基于Fiddler的流量分析,用于逆向工程社交平台上的API调用。为了应对反爬机制,该系统采用了IP代理轮换、动态头部注入和基于Tor的暗网访问等技术。从网站、社交媒体平台和深网等来源的数据,通过分布式架构收集,利用容器化部署和SOCKS5代理确保系统的可扩展性和可靠性。预处理阶段包括自动化的数据清洗、标准化和格式转换,这些过程由分布式消息队列支持,确保数据能够实时传输到下游系统。
数据收集中包含了多种API,每个API都设计用于与特定类型的数据源接口。这些API包括用于抓取社交媒体平台(如Facebook、Twitter、Instagram和LinkedIn)的端点,能够提取用户资料、帖子、评论、关注者和地理位置信息。对于深网和暗网数据,系统集成了能够访问Tor启用站点并使用定制浏览器自动化进行自动数据提取的API。新闻和论坛数据通过支持基于模板的URL生成的API收集,实现全站抓取,从而提取标题等结构化信息,内容和时间戳。此外,基于应用程序的数据收集API允许通过UIAutomator2或类似框架与移动应用进行交互,捕捉用户活动、帖子和其他元数据。每个API都配备了反爬虫措施,如IP轮换和会话模拟,确保对各种数据类型的稳健和适应性访问。这些API共同支持从结构化、半结构化和非结构化来源获取全面数据,以满足情报任务的多样化需求。

图3:数据采集子系统结构
除了数据收集,该系统还集成了数据预处理模块,以优化和标准化多源数据。清洗模块利用机器学习技术检测缺失值、冗余和逻辑错误等问题,并动态应用异常检测、填补和模糊匹配等解决方案。元素提取模块基于OPL(对象-属性-关系)模型和自然语言处理技术,解析关键信息并映射到标准字段,识别关系并提取有效元素。格式转换模块自动检测并转换各种格式(如JSON、XML、CSV),以标准化数据结构。对于冗余和冲突,去重模块通过相似性计算和哈希算法实现高效去重,使用优先规则和智能合并解决冲突。最后,聚合模块对数据进行分类和聚类,完成属性关系的建立,生成高质量、标准化的数据集。
3.2 领域知识图谱与动态查询机制
领域知识图谱是整合和管理多源结构化及非结构化数据的核心组件。它基于资源描述框架(RDF)标准构建,确保了不同数据类型之间的语义一致性和兼容性。后端采用高性能图数据库Neo4j,能够高效地存储、检索和遍历复杂关系。
动态查询机制为与知识图谱的高效互动提供了灵活的支持。用户或系统可以使用Neo4j的Cypher查询语言来检索复杂的关联模式或特定领域的洞察。此外,知识图谱支持增量更新,持续整合新的数据源,以保持其实时相关性和适应不断变化的情报需求。
3.3 基于LLM的交互式OSINT代理
OSINT代理采用了一种模块化架构,旨在提高适应性和效率。该系统集成了内存模块、领域特定的知识图谱、工具自动化以及自我反思的反馈机制,从而构建了一个强大的实时市场情报解决方案。图4展示了所提出的OSINT代理的整体工作流程。
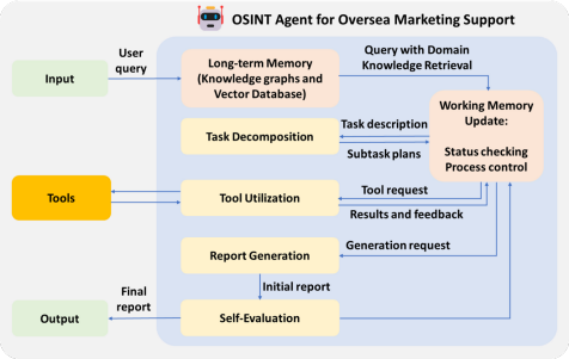
图4:OSINT代理的工作流程
3.3.1 语义理解
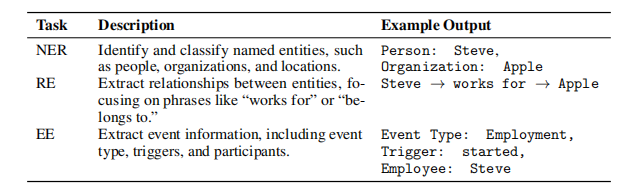
基于文本的提示工程策略用于从非结构化文本中提取结构化的领域特定属性信息。这一过程涉及三个关键的自然语言处理任务:命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)。
●NER旨在识别和分类文本中的命名实体,如人、组织和地点。
●RE专注于识别实体之间的关系。RE提示旨在识别表达关系的短语,例如“适用于”、“属于”或“与...相比”。
●EE提取事件信息,包括事件类型、触发器和参与者。EE提示主要关注提取事件的起始位置。
表1中给出了三个任务的示例。
在执行这些任务时,LLM会处理自然语言提示和非结构化文本表示,生成准确且全面的结构化输出。提取的输出可以被组织并更新到知识图谱中,作为节点(实体)和边(关系),同时支持后续分析。
3.3.2 内存
内存模块确保了在迭代分析任务中上下文的连续性,使系统能够生成一致且与上下文相关的见解。通过利用LangChain的内存机制,如对话缓冲记忆和对话摘要记忆,系统能够高效地保留历史上下文和中间结果,这些信息被动态用于多轮推理和报告生成。
表1:结构化信息提取任务示例
3.3.3 知识
知识图谱和向量数据库为代理提供专业指导,同时基于工作记忆模块持续更新,支持检索增强生成(RAG),并在生成任务期间动态向LLM提供必要的知识,在此过程中,不同的数据源被转换为可操作的智能。
为了提高效率,系统采用了一个基于提示的属性提取表,确保领域类型与属性之间的精确对应。该表支持新领域的动态扩展,只需更新领域记录、属性和预设提示模板即可。例如,添加“技术”领域时,只需定义相关属性和提示,即可实现无缝集成。
系统首先通过表格确定来自不同来源(如新闻、智库报告)的数据的领域类型,确保分类和模板选择的准确性。接着,系统生成定制化的提示,以提取特定领域的属性,例如经济领域的预算或政治领域的组织结构。这些提取的属性被整合到知识图谱中,丰富了其结构。
通过将提示表与RAG结合,向量数据库在属性提取过程中能够动态检索补充的多源信息。这不仅提升了上下文理解、准确性和完整性,还使系统能够更有效地处理复杂数据集。这些机制的整合确保了精确且适应性强的领域知识提取,同时支持系统的扩展和创新。
3.3.4 工具自动化
工具自动化在数据采集过程中扮演着至关重要的角色。通过整合第3.1节提到的高级自动化工具,代理能够从社交媒体、新闻网站和政府报告等不同来源,通过API接口和自动化爬虫脚本收集实时数据。这些原始数据经过基于Python的预处理框架的清洗和结构化处理,确保其适合后续分析和知识图谱的整合。
3.3.5 自我反思
为了提升报告生成的质量,我们引入了一种自主反馈机制,旨在通过自我反思使系统能够迭代优化其性能。该机制利用LangChain的反馈循环,基于事实准确性、可读性和相关性这三个关键指标来评估输出。评估可以通过人工反馈或预设规则进行,这些规则被系统地整合到工作流程中,以确保持续改进。然而,由于LLM骨干网络中存在的数据偏差和幻觉问题,这些问题与OSINT任务对高准确性的要求相冲突,因此,自评估指标的制定及其有效性以及系统开发仍然是一个重大挑战。
一般来说,通过将最先进的LLM骨干与OSINT工具集成,代理可以动态检索和处理相关数据,以提高其洞察力的深度、准确性和精确性。将模块化架构与LangChain的高级功能相结合,所提出的OSINT代理代表了实时市场情报的有效、适应性和智能解决方案。
4.实验与结果
4.1 目标与实验设计
实验的主要目标是评估所提议系统的功能和性能,特别是其从不同来源收集和处理数据的能力,以及提取信息的质量。为了达到这一目的,我们设计了预定义的任务,这些任务模拟了现实世界中的操作系统情报(OSINT)场景,包括从网站和社交媒体平台收集数据,以及在多个领域中提取信息,如人物资料、组织结构、事件摘要和实体关系。
这些OSINT任务的特点是复杂性和综合性,要求系统在不同维度上展示强大的数据处理和分析能力。具体而言:
1.人物简介:这项任务涉及识别和聚合个人信息,如姓名、职务、所属机构和主要成就。它要求精确的实体识别和关系提取,并能有效解决来自多个数据源的冲突信息。
2.组织结构:提取组织内部的层级关系通常需要解析结构化和非结构化的数据,包括文本描述、表格和图像。此外,这项任务还涉及处理多组件实体、分层的组织结构以及复杂的结构关系。
3.事件总结:从新闻文章和社交媒体等不同数据流中识别关键触发因素、参与者和上下文细节,从而总结事件。
4.实体关系:映射和分析实体间的关系,例如协作、隶属或依赖关系,需要系统理解并建模复杂的相互联系。这项任务高度依赖推理和抽象能力,以推断那些虽未明确表述但对生成可操作情报至关重要的关系。
通过在这些维度上设计任务,实验旨在评估系统应对OSINT场景中固有的多样性和复杂性的能力。通过这些任务,我们还旨在测试系统在解决现实世界情报挑战时的适用性和可扩展性。
4.2 评价方法
目前,系统性能主要通过人类反馈进行评估,专家手动评估输出,这可能需要进一步的改进。
人类反馈评估由五位领域专家组成的团队进行,他们手动审查了系统的输出。在评估过程中,从四个预定义类别中选取了200个结果。为了衡量准确性,专家们采用了一种二元评分系统,完全正确的生成内容得1分(正确),而任何包含错误信息的内容则得0分(错误)。
使用以下公式计算系统的准确率:
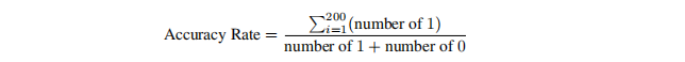
表2给出了由专家评估的每种结果类型的准确率统计,评估结果提供了系统在不同任务中的性能洞察,突出了优势领域,并指出了未来改进的潜在弱点。
表2:专家评价的不同结果类型准确度

4.3 观察与分析
对错误结果进行进一步分析后,确定了当前系统的主要缺陷:
1.来自不同来源的矛盾信息:尽管优先规则和智能合并技术缓解了一些冲突,但系统在处理更复杂的情况时仍面临挑战。当同一知识点(如个人资料)出现在多个数据源中,例如维基百科、官方网站或新闻平台时,系统依赖最新信息。然而,如果最新数据未经验证或存在矛盾,这种依赖可能会导致不准确,最终影响输出的一致性和可靠性。
2.多模态信息整合不足:关键信息,如组织结构,通常以非文本形式呈现,例如图像或嵌入网页表格中。由于缺乏光学字符识别(OCR)或基于图像的提取机制,系统无法处理这些格式,导致提取的组织结构和关系数据出现遗漏或不完整。
3.噪音与虚假信息:系统可能从多种来源收集假新闻或不可靠的新闻文章,这不仅引入了数据集中的噪音,还扭曲了事件摘要等提取的信息。由于缺乏有效的事实核查和来源验证机制,虚假信息的影响进一步加剧,从而影响了系统输出的整体可靠性。
4.有限的因果推理能力:尽管系统在摘要方面表现良好,但目前仍无法进行因果关系和更抽象的推理,这对于理解和分析事件与实体之间的复杂关系至关重要。例如,识别一个事件如何触发另一个事件,或实体如何随时间相互影响,需要高级推理和预测建模。
5.自我评估和错误纠正能力有限:系统在自我评估、识别自身错误并实施纠正方面的能力尚不成熟。具体而言,系统缺乏有效的错误归因机制(即确定不准确性的根本原因),以及动态修正错误输出的策略。这些不足限制了系统迭代改进和适应变化或错误数据的能力,从而影响其长期可靠性和扩展性。
识别出的局限性指出了当前系统需要改进的关键领域,以充分发挥其作为强大OSINT解决方案的潜力。例如,来自不同来源的信息冲突、多模态集成不足以及噪声和虚假信息的存在,都凸显了加强数据验证、多模态处理能力和可靠事实核查机制的重要性。此外,缺乏因果推理、自我评估和错误纠正功能,限制了系统生成更深入见解和迭代提升性能的能力。解决这些问题对于提高系统的适应性、可扩展性和整体智能至关重要,使系统能够更准确、更可靠地应对日益复杂的现实场景。
5.讨论
所提出的OSINT系统展示了在整合领域知识图谱、动态查询机制和基于大型语言模型(LLM)的能力方面,能够高效处理多源数据并提取情报的潜力。然而,该系统仍存在一些局限性,这些局限性为未来的改进提供了机会。本节将深入探讨该系统设计与性能的广泛影响,分析其当前的优势、面临的挑战以及未来可能的发展方向。通过反思在这些方面,我们的目标是全面了解系统的影响力,并确定新兴技术可以利用的领域,以最大限度地提高其效用和适应性。
5.1 多模态处理
该系统目前还缺乏有效处理多模态信息的能力,尚未整合处理文本、图像、视频和音频等多样化数据格式的机制。未来若能将多模态信息编码器纳入系统,将能够处理并融合不同类型的异构数据,从而提升系统的整体分析能力。
5.2 更加自动化的评估
例如,部署专门的评估代理可以进一步减少人工劳动并提高效率。挑战包括开发全面合理的定量评估指标体系、提高基于LLM的自主评估的准确性和可靠性、确保在不同任务和领域的一致性。
5.3 更准确的生成对抗偏见和错觉
尽管语言模型(LLMs)已经取得了显著的进步,但它们在生成的输出中仍面临偏见和幻觉的问题。未来的研究应着重于整合外部知识验证机制和实时事实核查模块,以减少偏见并提高内容的可靠性。诸如检索增强生成(RAG)、对抗训练和多源交叉验证等技术,在解决这些问题和确保输出事实准确性方面发挥着关键作用。
5.4 更高级的自学能力
当前系统自学习能力有限,严重依赖预先设计的手动机制作为先验知识,例如精心组织的提示。未来的发展可以引入强化学习和自适应算法,减少人工干预,使系统能够从不断变化的数据模式和反馈中动态学习。
5.5 多代理协作
多代理系统(MAS)为增强操作性情报(OSINT)解决方案的适应性和可扩展性提供了广阔的机会。未来的研究应着重于设计具有特定角色的代理,如数据收集者、处理者、评估者和决策者,并通过动态任务分配和通信协议实现无缝协作。面临的挑战包括优化资源调度、确保容错能力,以及开发能够适应数据源和任务复杂度实时变化的稳健交互策略。将多代理系统与大型语言模型(LLMs)结合,可以利用集体智慧来提高系统性能,特别是在处理复杂的大规模任务时。
6.结论
在本研究中,我们提出了一种模块化的OSINT代理框架,该框架集成了领域知识图谱、动态查询机制和基于大型语言模型(LLM)的高级功能,旨在应对实时多源数据智能的挑战。系统利用RDF标准和Neo4j构建并管理一个灵活且语义丰富的知识图谱,确保兼容性和高效的数据检索。通过引入提示驱动的属性提取和特定领域的模板,系统能够以最少的人工干预动态适应新领域和属性。此外,检索增强生成(RAG)技术的整合,通过从向量数据库中动态检索补充数据,提高了信息提取的准确性和上下文相关性。这些组件共同构成了一个高效的管道,用于数据清洗、领域分类、信息提取、分析和标准化。
未来的工作将重点放在进一步自动化评估机制,并通过增强的多代理协作和先进的反馈循环来优化系统的性能。通过采用尖端技术,该框架为长期OSINT创新和在不同场景中的应用提供了坚实的基础。
参考文献
[1]Mohammed Ogab Mohammed ALharthi.The role of digital knowledge tools (osint) inraising the efficiency of organizations. International Multilingual Academic Journal,1(1), 2024.
[2]Thomas Oakley Browne, Mohammad Abedin, and Mohammad Jabed Morshed Chowdhury.A systematic review on research utilising artificial intelligence for open source intelligence (osint) applications. International Journal of Information Security, pages 1–28, 2024.
[3]Central Intelligence Agency. INTelligence: Open Source Intelligence. Historical Document, 2010.Archived at: https://web.archive.org/web/20200303002208/
https://www.cia.gov/news-information/featured-story-archive/2010-featured-story-archive/open-source-intelligence.html.
[4]Steve Micallef. Spiderfoot.https://github.com/smicallef/spiderfoot/releases, 2021. Accessed: 2024-06-17.
[5]Maltego. Maltego. https://www.maltego.com/, 2022. Accessed: 2024-06-17.
[6]Ahmed Aboul-Ela. Sublist3r.https://github.com/aboul3la/Sublist3r, 2020.Ac- cessed: 2024-06-17.
[7]Hany Ahmed, Issa Traore, and Sherif Saad. Detection of online fake news using n-gram analysis and machine learning techniques. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), volume 10618 of LNCS, pages 127–138. Springer, December 2017. doi: 10.1007/978-3-319-69155-8_9.
[8]Shivangi Goel, Niharika Sachdeva, Ponnurangam Kumaraguru,A. V. Subramanyam, and Deepti Gupta. Pichunt: Social media image retrieval for improved law enforcement. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), volume 10046 of LNCS, pages 206–223. Springer, 2016. doi: 10.1007/978-3-319-47880-7_ 13. arXiv:1608.00905.
[9]Chhavi Choudhary, Ranjith Sivaguru, Miguel Pereira, Bin Yu, André C. Nascimento, and Martine De Cock. Algorithmically generated domain detection and malware family classi- fication. In International Symposium on Security in Computing and Communication (SSCC 2018): Security in Computing and Communications, pages 640–655. Springer, 2019. doi: 10.1007/978-981-13-5826-5_50.
[10]Wen Yang and Kwok-Yan Lam. Automated cyber threat intelligence reports classification for early warning of cyber attacks in next generation soc. In Lecture Notes in Computer Science (LNCS), volume 11999, pages 145–164. Springer, 2020. doi: 10.1007/978-3-030-41579-2_9.
[11]C.S.PavanKumar and L. D. DhineshBabu. Novel text preprocessing framework for sentiment analysis.In Smart Innovation,Systems and Technologies,volume 105, pages 309–317. Springer, 2019. doi: 10.1007/978-981-13-1927-3_33.
[12] Eric Marin, Mohammed Almukaynizi, and Paulo Shakarian. Inductive and deductive reasoning to assist in cyber-attack prediction. In 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), pages 262–268. IEEE, 2020. doi: 10.1109/CCWC47524. 2020.9031154.
[13] N. Ekwunife and N. Ekwunife.National security intelligence through social network data mining. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data 2020), pages 2270–2273. IEEE, 2020. doi: 10.1109/BigData50022.2020.9377940.
[14]Yuheng Cheng, Ceyao Zhang, Zhengwen Zhang, Xiangrui Meng, Sirui Hong, Wenhao Li, Zihao Wang, Zekai Wang, Feng Yin, Junhua Zhao, et al. Exploring large language model based intelligent agents: Definitions, methods, and prospects. arXiv preprint arXiv:2401.03428, 2024.
[15]H. Chase. Langchain, 2022. URL https://github.com/hwchase17/langchain.

