
 由
Anna-Search
发布于
2025年05月21日
由
Anna-Search
发布于
2025年05月21日
OmniPlacement:昇腾超大规模MoE模型推理 负载均衡技术报告
OmniPlacement:昇腾超大规模MoE模型推理
负载均衡技术报告
KenZhang,蔡丛志,陶壮,邝文威,姚钧夫,陈星源,王鹏程
2025年5月20日
目录
1、问题背景
2、技术方案
2.1基于计算均衡的联合优化
2.2层间高频专家冗余部署
2.3近实时调度与动态监控机制
3、推理加速套件:OmniPlacement
4、测试结果
5、结论与未来工作
图表目录
1、Longbench数据集不同层的专家激活次数分布
2、相同数据条件下,EPLB与OmniPlacement算法,每层设备最大激活数理论对比
3、不同冗余层数策略的最大激活降低理论值
4、冗余不同层数排布的理论热力图
5、启用一次近实时调度示例流程
6、动态数据收集功能Profiling示意图
7、近实时调度理论效果与收敛性
8、动态专家调度的多层间流水排布方案
9、OmniPlacement模块与流程
10、OmniPlacement与基线和BestEP的性能对比
1、问题背景
混合专家(MixtureofExperts,MoE)模型通过将计算任务分配给多个专家子网络,结合稀疏激活机制,降低了计算复杂度,同时保持了与稠密模型相当的性能。
在MoE模型的推理过程中,存在资源利用问题,表现为以下几个方面:
l 负载不均:部分专家(热专家)被频繁调用,而其他专家(冷专家)使用率较低,频率差距达到一个数量级以上(见图1)。
l 推理延迟增加:过载计算节点形成性能瓶颈,导致端到端推理时延增加
l 吞吐量受限:资源利用不均衡制约了系统整体吞吐能力。
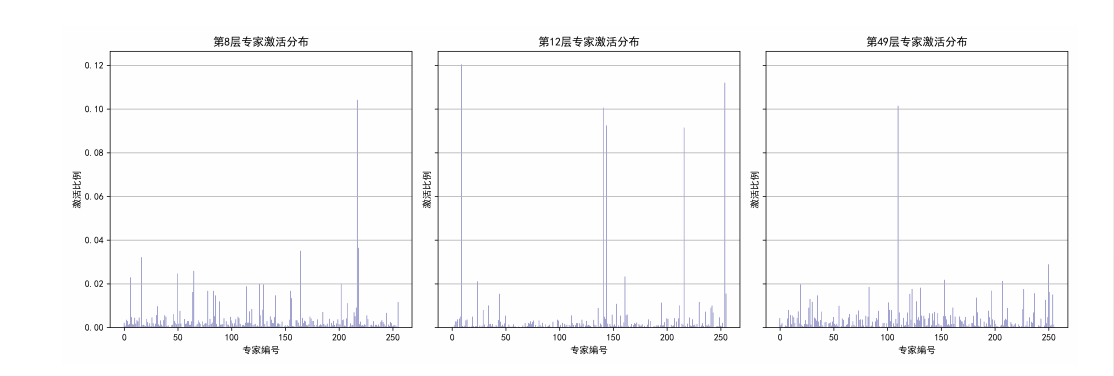
图1:Longbench数据集不同层的专家激活次数分布
近期研究中,DeepSeek-AI在DeepSeekV3模型[1]中针对负载均衡问题提出了一种算法EPLB[2],实现了较高的性能表现。基于此,本研究提出了一种负载均衡算法OmniPlacement,通过专家重排列、层间冗余部署以及近实时动态调度,在连续三个token推理步数区间内实现90%的负载均衡度,从而提升了混合专家(MoE)模型的推理效率。OmniPlacement的相关源代码将逐步向公众开放。
2、技术方案
为应对MoE模型推理中的负载不均问题,我们设计了一种基于层间非均匀冗余的优化方案,以较低的显存开销实现动态负载均衡和系统鲁棒性。方案包含以下技术模块:
2.1基于计算均衡的联合优化
通过分析专家激活数据,识别出高频调用的专家(热专家)和低频调用的专家(冷专家),并提出了一种基于计算均衡的算法OmniPlacement。该算法根据专家调用频率和计算需求优化部署顺序,减少负载不均现象。假设我们有R张卡,L个MoE专家层,E个不同专家编号数,我们定义专家放置矩阵P为三维张量P[卡编号r][MoE层编号l][专家编号e]=0或者1,其中1代表专家e放置于层l的卡d,0表示没有在该卡放置。我们对于专家排布有如下两个限定:
l 层内每卡专家数相同:对于每一个专家层内部,我们要求每卡的部署专家数目相同。如果该层每卡冗余s个位置,则该层一共有s×R个位置用于放置冗余专家。
l 每张卡上的部署专家编号均不相同:我们限定每张卡上的专家编号均不相同,保证了专家放置矩阵P取值为0或者1。
专家激活D是一个二维张量D[MoE层编号l][专家编号e]=y,表示一段时间内,层l的专家e的激活次数为y,我们对于这个值进行了预处理,使得更符合实际的计算流水。在给定专家放置P和专家激活D时,Ri(e,P,D)表示在P和D下卡i在层e的总计算负载,我们定义一个时间段内层E的负载均衡度为B(e,P,D)=maxiRi(e,P,D),其中i遍历所有卡。在给定每层的冗余预算下,我们希望最小化每层的负载均衡度B(e,P,D)。算法流程见算法1。
具体而言,该算法具有以下特点:
算法1 OmniPlacement算法流程
Input:初始专家激活计数D0,MoE层数L,卡数R
Output:初始专家放置P0
Goal:对每一层l最小化B(l,P,D0)=maxiRi(l,P,D0)


l 动态优先级调整:通过实时统计专家调用频率,动态调整专家的优先级和节点分配,确保高频专家部署在计算能力较高的节点上。
l 通信域优化:算法分析批次内激活卡数,优化跨节点通信域的范围,降低通信延迟。相较于静态分配方法,该算法减少了通信开销。
l 层间差异化部署:根据负载特性配置不同层的专家部署策略,支持非均匀冗余次数,适应层间负载差异。
本算法的特点包括:
l 动态适应性:算法通过动态调整专家优先级和节点分配,实现部署状态的快速收敛。
l 理论特性:在负载分布均匀性和收敛性方面具有理论支持,通过迭代优化实现资源利用(见图2)。
l 并发支持:在高并发场景下,通过分步骤调整专家部署,降低部署时延,优化计算效率。

图2:相同数据条件下,EPLB与OmniPlacement算法,每层设备最大激活数理论对比
通过上述设计,该算法在理论和实践上均实现了负载均衡,适用于大规模MoE模型的高负载推理场景。
2.2层间高频专家冗余部署
为解决热专家的高频调用压力,我们实现了层间(layer-wise)冗余部署策略,通过为高频调用专家分配冗余实例,降低跨节点通信开销,优化系统吞吐量。该策略的特点包括:
l 动态资源分配:根据实时计算资源占用情况和专家调用频率,动态调整冗余实例的分配比例,缩小冷热专家间的性能差距。
l 层间差异化配置:根据负载需求配置不同层的冗余次数,适应层间负载差异。例 如,高负载层分配更多冗余实例,而低负载层则减少冗余以节省显存,图3表示冗余不同层数排布的层内每卡总激活数最大值的理论变化,图4表示冗余不同层数排布的理论每层每卡激活热力图。
l 预测性分配:结合历史激活数据和负载预测模型,提前优化资源分配,减少突发负载对系统性能的影响。

图3:不同冗余层数策略的最大激活降低理论值

图4:冗余不同层数排布的理论热力图
相较于EPLB的统一冗余分配策略,本方法的特性包括:
l 资源利用:通过动态调整冗余实例,优化硬件资源利用,减少显存占用。
l 系统鲁棒性:预测性分配机制支持系统适应输入数据的动态变化,保持性能稳定。
l 灵活性:层间差异化配置实现精细化资源管理,适用多种MoE模型架构。
通过上述设计,该策略优化了系统吞吐量和稳定性,适用于高负载MoE推理。
2.3近实时调度与动态监控机制
近实时专家激活是实现动态均衡的基础。基于昇腾平台,我们设计了一套近实时调度与动态监控机制,在维持推理性能的前提下收集和分析专家激活信息,示例流程(见图5),整个调度机制包含以下子模块:
l 动态监控:实时跟踪专家激活数据和系统资源占用,为调度决策提供依据。监控任务在独立的计算流中运行,避免干扰推理主流程,维持系统整体效率(见图6)。
l 近实时调度:通过实时统计数据流特性,动态调整专家分配以适应输入数据变化。在给定数据分布内,动态调度算法在两到三次调用后收敛到静态专家部署模式,优化推理过程的高效性和一致性(见图7)。
l 动态专家权重调整:通过层间流水线设计,实现专家权重和分配的动态更新。系统并行处理权重更新和数据流分配,支持专家动态调整。流水线设计支持在不中断推理流程的情况下完成权重更新,降低高负载场景的推理延迟(见图8)。
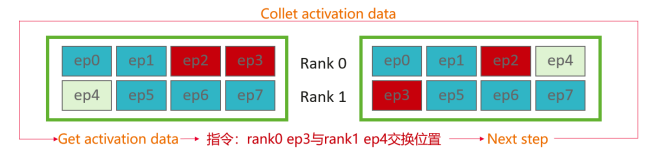
图5:启用一次近实时调度示例流程

图6:动态数据收集功能Profling示意图
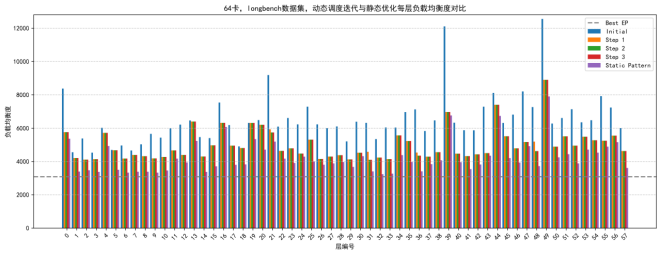
图7:近实时调度理论效果与收敛性
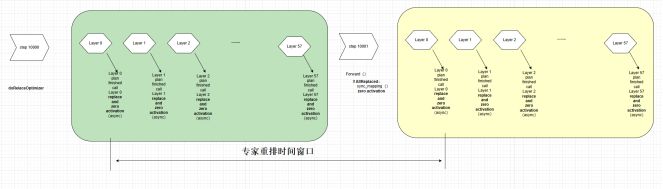
图8:动态专家调度的多层间流水排布方案
上述机制通过并行处理和快速收敛,优化了系统的动态适应性和推理性能。监控与调度分离的设计避免了监控任务对推理延迟的影响,提升了系统的鲁棒性。
3、推理加速套件:OmniPlacement
在实际部署中发现,动态专家均衡的应用,除算法设计外,需实现与模型脚本及推理框架的集成,支持模型推理的稳定运行。我们开发了解耦且适配昇腾平台的推理加速套件OmniPlacement,优化昇腾上动态专家负载均衡的部署:
l 兼容性:套件支持多种MoE模型架构,可集成至现有的推理系统。
l 时延优化:通过优化数据处理和调度流程,减少额外计算开销,维持推理性能。
l 模块化设计:套件包含数据统计、算法运行和专家调度三个模块,功能解耦,支持扩展和维护,便于迭代和定制开发(见图9)。
l 可扩展性:支持动态添加负载均衡算法和调度策略,适应MoE模型的需求。
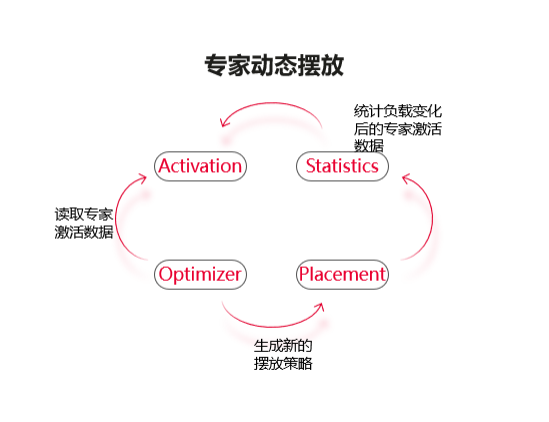
图9:OmniPlacement模块与流程
OmniPlacement通过模块化架构实现核心算法与推理流程的解耦,为大规模MoE模型推理提供基础设施。套件的设计将负载均衡功能与推理主流程分离,兼顾性能与灵活性。OmniPlacement推理加速套件将在近期开源。
4、测试结果
在昇腾平台上验证了OmniPlacement方案的性能:
l 推理延迟:相较于未优化负载均衡的MoE模型,推理延迟降低约10%。延迟优化源于动态专家分配和通信域优化,改善了用户体验(见图10)。
l 吞吐量:系统吞吐量增加约10%,源于资源利用的优化。特别是在高并发场景下,冗余部署和动态调度缓解了负载瓶颈。
l 系统稳定性:在动态输入和高负载场景下,系统维持稳定运行,未发生性能波动或服务中断。动态监控机制支持系统对突发负载的响应。
分析表明,OmniPlacement适应多种MoE模型和输入数据分布。实验结果验证了该方案在推理性能、资源利用和系统稳定性方面的性能优化,支持大规模MoE模型部署。
5、结论与未来工作
本研究通过专家重排、层间非均匀冗余部署、近实时调度和动态监控,解决了MoE模型推理中的负载不均问题,为大规模MoE模型推理提供了技术方案。实验数据表明,OmniPlacement在推理延迟、吞吐量和系统稳定性方面实现了性能优化,支持了MoE模型在多种应用场景中的部署。
未来研究将重点关注以下方向:
l 调度算法优化:设计高效调度算法,通过集成多样化策略,提升系统对动态输入的适应性。
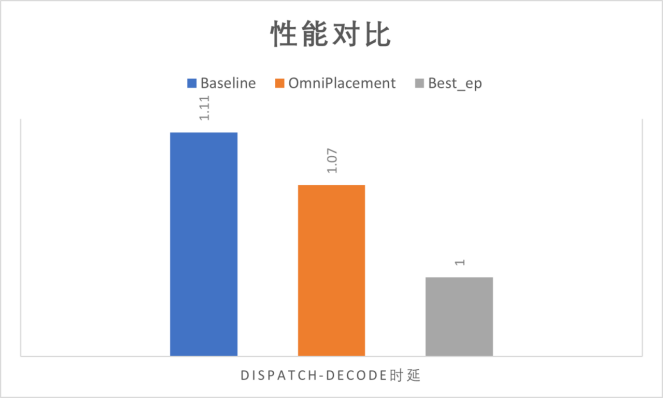
图10:OmniPlacement与基线和BestEP的性能对比
l 自适应专家选择:研究基于输入特征的专家选择机制,优化专家激活策略以适应不同推理场景。
l 框架扩展:增强OmniPlacement的兼容性,支持多种MoE模型架构并提升通用性。
参考文献
References
[1]DeepSeek-AI,“Deepseek-v3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2412.19437
[2]——, “Expert parallelism load balancer,”2025. [Online]. Available:
https://github.com/deepseek-ai/EPLB.[Accessed:May20,2025].[Online].Available:
https://github.com/deepseek-ai/EPLB

