
 由
Anna-Search
发布于
2025年06月29日
由
Anna-Search
发布于
2025年06月29日
COSINT代理:一种基于知识的中国开源情报多模态代理

摘要
开源情报(OSINT)需要整合和分析多种多模态数据,这在提取可操作见解时面临重大挑战。传统方法,如多模态大型语言模型(MLLMs),往往难以从非结构化数据源中推断复杂的上下文关系或提供全面的情报。本文介绍了一种名为COSINT-Agent的知识驱动型多模态代理,旨在解决中文领域OSINT的挑战。COSINT-Agent将微调的MLLMs的感知能力与实体-事件-场景知识图谱(EES-KG)的结构化推理能力无缝结合。COSINT-Agent的核心是创新的EES-Match框架,该框架连接了COSINT-MLLM和EES-KG,能够系统地提取、推理和上下文化多模态见解。这种集成有助于精确识别实体、解释事件和检索上下文,有效地将原始多模态数据转化为可操作的情报。广泛的实验验证了COSINT-Agent在核心OSINT任务中的卓越表现,包括实体识别、EES生成和上下文匹配。这些结果突显了其作为强大且可扩展解决方案的潜力,有助于推进自动化多模态推理并提高OSINT方法的有效性。
WentaoLi1 2 CongcongWang1 XiaoxiaoCui1 2 ZhiLiu1 2 WeiGuo12 LizhenCui12
1.山东大学软件学院,济南,中国;
2.山东大学联合SDU-NTU人工智能研究中心(C-FAIR),中国。
通讯作者:刘志<liu-zhi@sdu.edu.cn>,崔丽珍<clz@sdu.edu.cn>。
第41届国际机器学习会议论文集,加拿大温哥华。PMLR267,2025年。版权所有©2025作者(们)。

图1.(a)输入图像由主流语言模型处理,这些模型能够生成基本的场景描述,但在深入分析实体、事件和上下文方面存在不足。(b)相比之下,COSINT-Agent通过整合EES-KG(扩展知识图谱),能够进行更细致的分析,不仅识别场景,还能识别与图像相关的事件和背景。为了清晰起见,提供了英文翻译,但这些翻译不构成原始输入或输出的一部分。
1.导言
开源情报(OSINT)是指从多种来源系统地收集、分析和解释公开数据的过程(Ghioni等,2024)。随着文本、视觉和社交媒体等多样化数字内容的迅速增长,OSINT在多个领域的重要性日益凸显,包括灾害响应(Zhou等,2022)、打击网络犯罪(Nouh等,2019;Cartagena等,2020)、提升网络安全威胁意识(Govardhan等,2023;Jesus等,2023;Riebe等,2024)、情感分析(Hernandez等,2018)以及风险评估(Delavallade等,2017)。从大量多模态数据集中高效提取可操作信息的能力,为决策制定和情境感知提供了巨大的潜力。
尽管操作性情报(OSINT)具有广阔的应用前景,但由于数据的异质性和海量规模,以及其应用的必要性,有效实施OSINT仍是一项极具挑战性的任务。在上下文推理方面,现有的OSINT分析主要依赖于基于规则的系统、传统机器学习(Ndlovu等,2023)和深度学习方法(Zhou等,2022),这些方法在处理复杂和非结构化的多模态数据时,缺乏必要的适应性和可扩展性。尽管多模态大型语言模型(MLLMs)在统一文本和图像分析方面展现出巨大潜力,但其在OSINT领域的应用仍面临两大挑战。首先,MLLMs容易产生幻觉(Ji等,2023),生成事实错误的输出(Mondal等,2024),并且缺乏整合最新领域知识的能力(Pan等,2024),这削弱了它们在动态OSINT任务中的可靠性。其次,这些模型仅限于生成图像的表面描述,无法深入推断图像中所描绘事件的深层含义。例如,如图1所示,主流大型语言模型——通义问答1、Kimi2、豆包3、文心一言4和ChatGPT5——通常生成泛化的场景描述,如“这是一个色彩斑斓的表演场景。”虽然这些输出提供了对图像的表面理解,但未能识别出具体事件或所描绘的上下文细节。
1.网址:https://tongyi.aliyun.com/
2.网址:https://kimi.moonshot.cn/
3.网址:https://www.doubao.com/chat/
4.网址:https://yiyan.baidu.com/
5.网址:https://chatgpt.com/
为应对这些挑战,我们提出了COSINT-Agent,这是一种专为OSINT任务设计的知识驱动型多模态智能代理。通过将微调的MLLM与实体-事件-场景知识图谱(EES-KG)相结合,COSINT-Agent减少了幻觉和过时知识的影响,通过准确且特定领域的上下文增强了推理能力。经过两阶段的微调,我们提高了模型对实体类型的识别和EES生成的准确性。COSINT-Agent确保通过最新的OSINT知识图谱整合最新信息,为动态智能场景提供了一个强大的解决方案。COSINT-Agent利用EES-Match框架克服了生成表面图像描述的局限性,该框架使COSINT-MLLM能够与EES-KG协作。这使得COSINT-Agent能够从视觉数据中提取更深层次的语义意义,识别出所描绘的事件、其时间和空间背景及其更广泛的影响。如图1所示,COSINT-Agent分析了第33届夏季奥运会开幕式的一张图片,不仅识别了实体(菲利普·卡特琳),还识别了事件(开幕式)、其时间和空间背景以及更广泛的文化含义。通过将先进的MLLM微调技术与知识图谱整合相结合,COSINT-Agent成功弥合了原始多模态数据与可操作智能之间的鸿沟,为OSINT应用提供了全面的解决方案。
我们的贡献可总结如下:
●我们提出COSINT-Agent,这是首个专为开源情报任务设计的基于多模态语言模型(MLLM)的智能代理。COSINT-Agent弥合了多模态数据分析与可操作情报之间的差距,为开源情报领域面临的挑战提供了创新解决方案,尤其在处理和推理多样化数据类型方面表现突出。
●我们提出了一种创新方法,通过EES-Match将大规模语言模型(MLLMs)与EES-KG集成,实现模型与知识图谱之间的无缝协作。这种协同效应显著提升了模型的多模态推理能力,使其能够从复杂的视觉和文本数据中提取更深层次的上下文信息。
●通过全面的实验,我们验证了COSINT-Agent在真实世界OSINT场景中的有效性和价值。实验结果表明,我们的方法在实体类型识别、图像EES生成以及通过EES-Match在EES-KG中进行上下文匹配方面具有可行性,展示了其作为OSINT应用强大工具的潜力。
2、相关工作
2.1 多模态知识图谱
多模态知识图谱(MMKGs)通过整合图像和文本描述等多模态数据,增强了传统知识图谱,提供了更丰富的实体表示,并支持复杂的推理任务。先前的研究表明,这些图谱在多个应用中表现出色,例如通过将实体特征与图像关联来完成知识图谱和进行三元分类(Xie等,2017;Mousselly-Sergieh等,2018),通过视觉-实体关系实现实体感知的图像描述(Zhao&Wu,2023),以及通过融合结构化知识与多模态内容来构建推荐系统(Sun等,2020)。最近的研究进一步探索了MMKGs在提升大型语言模型(LLM)推理能力方面的潜力。例如,MR-MKG(Lee等,2024)提出了一种多模态推理框架,该框架利用关系图注意力网络编码结构化知识,并通过跨模态语义对齐来连接文本和视觉信息。尽管这些研究主要集中在通过多模态知识增强LLM以完成特定任务,但我们的方法则通过实现实时结构化知识的处理来实现这一目标。通过EES-Match实现检索与推理。COSINT-Agent不被动整合多模态知识,而是主动匹配并检索EES-KG中的相关上下文信息,从而在LLM生成的表示与结构化事件驱动智能之间建立直接联系。通过EES-Match实现检索与推理。COSINT-Agent不被动整合多模态知识,而是主动匹配并检索EES-KG中的相关上下文信息,从而在LLM生成的表示与结构化事件驱动智能之间建立直接联系。
2.2 增强知识的大型语言模型
近年来,知识增强的大型语言模型(LLMs)通过整合结构化的外部知识,旨在减轻幻觉现象并提升推理能力。传统方法主要通过检索相关三元组,并将其转化为基于文本的提示,将文本知识图谱融入LLMs中,以增强下游任务的表现,如问答和实体识别。例如,Baek等人(2023)、Sen等人(2023)和Wu等人(2023)的研究表明,通过知识图谱到文本的转换,可以在不重新训练的情况下提高LLM的推理能力。然而,直接将知识图谱中的三元组注入LLM提示中,由于引入了无关或额外的上下文,往往会导致噪声,从而限制了这些方法的有效性(Tian等人,2024)。最近的研究,如Mondal等人(2024),将知识增强技术扩展到了多模态场景,利用文本知识图谱来增强多模态思维链任务中的推理能力。(Wen等人,2023)提出了一种名为MindMap的知识图谱提示技术,该技术能够引导LLM生成结构化的推理路径,提高透明度并减少幻觉现象。尽管这些方法提升了语言模型(LLM)的性能,但它们主要在文本知识表示层面运作,忽略了多模态知识图谱(MMKGs)的结构与语义丰富性。相比之下,我们的研究通过一种创新的EES-Match框架,将MMKGs整合到语言模型推理中,实现了多模态数据与特定领域结构化知识之间的结构化和自动化对齐。这种方法确保了LLM可以系统地检索、解释和推理文本和视觉知识,从而实现更健壮和上下文感知的OSINT分析。
3.COSINT代理
3.1 概述
本节概述了COSINT-Agent,这是一个专为处理和推理多模态COSINT数据而设计的核心系统。图2展示了该系统的流程图。COSINT-Agent系统由三个关键组件构成:EES-识别、EES-匹配和EES-KG。EES-识别利用微调的COSINT-LLM从多模态数据中提取EES,构建图像内容的结构化表示。EES-匹配通过将提取的EES元素与EES-KG(领域特定知识库)连接,实现多模态推理与结构化知识之间的无缝对接。这一过程使系统能够检索相关的上下文知识,从而增强其对综合数据的解读能力。通过将结构化推理与大规模多模态推理相结合,EES-KG提供了重要的上下文基础,增强了COSINT-Agent以更准确、可解释且情境感知的智能分析支持OSINT任务的能力。
3.2 数据集
为了支持COSINT-Agent的开发与评估,我们从多个开源平台收集了总计64,532条数据记录和70,346张相关图像,详见附录A。该数据集包含了多样化的开源信息,有助于构建稳健且准确的OSINT任务模型。为了进一步提升系统性能,我们构建了两个专门的指令数据集,其中指令数据是通过Chat-GPT4o及其他大型语言模型生成的:
1.实体(类型)识别数据集:
该数据集专门设计用于训练和评估实体及其相关类型的识别(如人物、组织、地点、物体等)。数据集中包含250,747个标注的实体,用于微调COSINT-LLM模型,显著提升了其识别与OSINT相关的关键实体的能力。此外,还精心准备了一个包含62,242个实体的测试集,以评估模型的泛化能力。数据经过了广泛的清理和过滤,并通过人工验证确保了高质量和相关性。
2.多模态EES数据集:
多模态EES数据集专注于从图像中提取EES,这对于构建EES-KG和实现无缝的多模态推理至关重要。该数据集包含3,225个标注样本,经过彻底的清理、过滤和最终的手动审查,确保数据的一致性和可靠性。它在微调COSINT-LLM以增强其描述复杂多模态上下文的能力方面发挥着关键作用。
3.3 MLLM微调
COSINT-Agent是基于Qwen2-VL-7B模型(Wang等,2024b)开发的,作为COSINT-MLLM的基础。采用Llama-Factory(郑等,2024)进行了一次结构化的两阶段微调过程,充分利用了此前构建的实体(类型)识别和多模态EES数据集。在第一阶段,模型通过使用实体(类型)识别数据集对模型进行了微调,旨在提升其在OSINT领域内识别关键实体及其类型的能力。这一阶段的指导微调显著增强了模型对基于文本的实体及其角色的基础理解,为后续任务奠定了坚实的基础。在第二阶段,我们进一步利用多模态EES数据集对模型进行了微调,以实现从多模态数据中有效识别和生成实体、事件及场景。这一阶段优化了模型感知复杂多模态信息的能力,并生成了适合与EES-Match框架集成的EES描述。主要的微调参数包括使用LoRA(Hu等人,2021)进行高效的参数更新,学习率为5×10^-5,训练周期为3,批量大小为2,梯度累积步数设为8,以及AdamW优化器以提高收敛稳定性。这种高效的设置确保了微调过程既高效又资源节约。两阶段微调的有效性在实验结果中得到了验证,附录中的损失曲线提供了额外的验证。第一阶段优化了模型的文本识别能力,而第二阶段则专注于多模态EES(电子情报系统)识别,提升了其在OSINT任务中的推理和描述准确性。这两个阶段共同显著增强了COSINT-Agent的多模态理解和生成可操作情报的能力,展现了其处理文本和视觉数据时的适应性和稳健性。
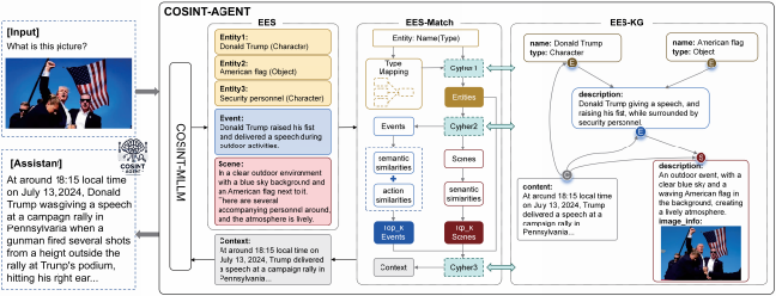
图2展示了COSINT-AGENT的推理过程,该系统首先使用COSINT-MLLM对图像进行EES分析,接着通过EES-Match过程将上下文与知识图谱匹配,最终输出推理结果。需要注意的是,英语不是输入或输出的一部分,这些信息是为了更好地说明而提供的。
3.4 EES-KG
为了展示EES-KG的有效性,我们以图2为例。该分层框架——实体层面、事件层面和场景层面——系统地提取、组织并表示多模态知识,从而促进MLLMs的推理能力。接下来,我们将逐一介绍每个层面,并附上相关的数学表示。
在实体层面,目标是识别并分类图像中的关键实体。这些实体从图像中提取,重点关注语义类别,如地点、组织、物体、人物、文档等。与传统的对象检测方法不同,我们的方法不依赖于边界框标注,而是强调每个实体的语义重要性。实体可以正式表示为:
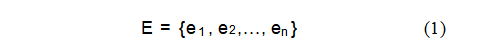
其中,E表示实体集。ei代表单个实体节点,表示为:ei =(id,type,name),其中id是该实体的唯一标识符,type表示实体类型(如人物、物体),name则是实体的标签(如唐纳德·特朗普、美国国旗)。在这个层级上,实体作为构建更高层次推理的基础,构成了后续层次的基础。
在事件层面,重点在于识别和描述图像中主要实体的关键事件。这些事件捕捉了实体之间的互动、行为或状态,以文本形式呈现。与传统事件检测方法不同,后者可能依赖时间标记或关系,我们的方法更侧重于事件内容本身,尤其是图像中实体的互动方式。涉及特定情境或活动。每个事件都由描述属性表示,详细记录了正在发生的事件。例如,该事件描述了唐纳德·特朗普发表演讲,并举起拳头,周围有安保人员。事件可以用数学方式表示为:
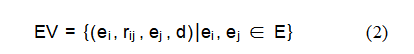
EV:事件集。ei和ej:参与该事件的实体。rij:实体之间的互动或行为。d:事件的文本描述。每个事件节点可以进一步定义为:ev=(id,实体,行为,描述)。在这个层面上,事件是理解场景动态的关键,为后续层次中的复杂上下文分析奠定了基础。
在场景层面,事件被整合成一个更广泛的上下文表示,捕捉高层次的语义,并结合时间、空间和环境背景,形成对图像的全面理解。通过融入位置、时间和额外背景信息等周围环境,场景层面增强了代理理解复杂多模态数据的能力,提高了其整体情境意识和感知能力。例如,考虑这样一个场景描述:一个户外活动,背景是晴朗的蓝天和飘扬的美国国旗,营造出一种生动的氛围。这个描述捕捉到了环境背景——晴朗的蓝天、飘扬的美国国旗和生动的氛围——提供了对场景更丰富的理解。该场景可以用数学方式表示为:

SC:场景表示。fscene:场景聚合函数,用于聚类相关事件并进行上下文化处理。场景节点可以描述为:sc=(id,事件,地点,时间,上下文)。在这个层面上,事件、实体和环境中的上下文化结合增强了多模态推理能力,提供了对场景的全面理解,从而提高了代理的情境意识。
在EES级别基础上,我们引入了“上下文”节点,该节点代表了图像在开源情报(OSINT)中的更广泛背景。上下文节点与所有实体、事件和场景节点相连,提供了与图像相关的地理、时间或情境等关键背景信息,这些信息来源于与图像相关的开源数据。上下文节点与每个节点的连接方式如下:
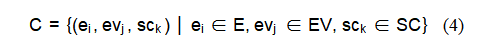
其中,E表示实体节点集合,EV表示事件节点集合。SC:场景节点集。C:与每个EES节点关联的上下文节点。
上下文节点最初并不属于EES节点,而是通过与EES节点的成功匹配动态获取。将匹配过程表示为函数fEES-Match,该函数根据识别出的实体、事件和场景来确定图像对应的上下文:
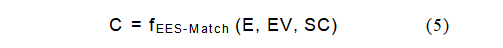
通过EES节点与上下文节点的成功匹配,系统可以检索相关的背景知识,从而对图像内容及其与更广泛事件、地点和时间框架的关系进行更全面的解释。
3.5 EES匹配
EES-Match模块作为COSINT-LLM与EES-KG之间的关键桥梁,建立了视觉内容与结构化知识之间的直接联系。这一集成充分利用了大语言模型(MLLMs)在多模态理解和生成能力上的优势,使得图像分析更加情境感知和深入。EES-Match过程旨在将实体、事件、场景和上下文等多模态数据层整合为一个全面的多模态推理系统。该过程分为多个阶段,通过类型映射和语义相似性评估,将实体与其在知识图谱中的对应事件和场景关联起来,最终检索出相关的上下文,如图2所示。以下是EES-Match过程的核心步骤:
在第一阶段,我们首先对EES数据中的实体进行结构化分析,通过解析它们的名称和类型属性。使用名称和类型可以确保实体的准确识别,避免因名称在不同领域中指代不同的实体而引起的混淆。例如,“小米”既可以指一种食品,也可以指一家科技公司,仅凭名称区分可能会导致误解。接下来,我们将相似的类型,如对象、项目、实体或地点、地理区域,映射到相应的类别中,确保相关实体能够被正确归类。名称和类型将转换为Cypher1查询语言格式,以便对知识图谱进行精确查询。具体的查询过程详见附录C.1中的算法??,该算法详细描述了构建和执行Cypher1查询以高效检索知识图谱中相关实体的步骤。这使得可以根据名称和类型检索所有匹配的实体,确保与知识图谱的全面匹配。
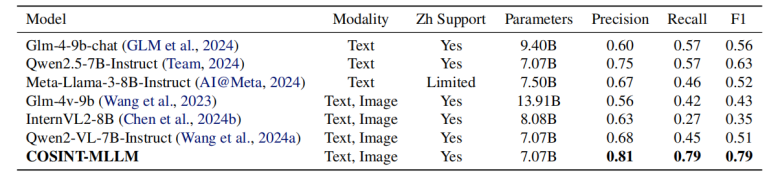
表1.展示了COSINT-MLLM在微调后的卓越表现,其性能超越了其他模型。实体识别任务的精确度、召回率和F1分数。
在检索到匹配的实体后,Cypher2查询被生成。为了识别知识图谱中的所有相关事件和场景,这些查询利用先前匹配的实体来提取它们相关的事件和场景,为多模态推理提供基础。详细的查询过程在附录中描述,如算法??所示,该算法介绍了将实体与其上下文事件和场景关联起来的结构化方法。对于事件,我们首先分析每个事件节点的描述字段,以识别涉及主要人物的关键行动或相关事件。第一步是计算行动特征相似度,这是通过计算事件与已识别实体的动作向量表示之间的余弦相似度来实现的:
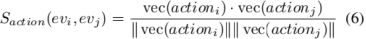
其中,Saction(evi,evj)表示事件evi和evj之间的动作相似度。vec(actioni)和vec(actionj)分别是实体和事件中动作的向量表示。接下来,我们计算事件描述的语义相似度,这衡量了实体上下文与整体事件描述的一致性。这一计算同样采用余弦相似度:
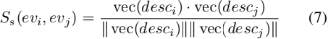
其中,Ss(evi,evj)表示事件描述desci和descj之间的语义相似度。vec(desci)和vec(descj)分别是这两个事件描述的向量表示。最终的事件相似度得分是通过结合动作相似度和语义相似度,并赋予适当的权重w1和w2来计算的,这些权重反映了各自相似度的相对重要性:
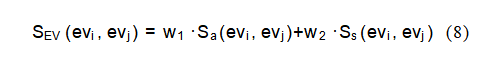
其中SEV(evi,evj)表示事件evi与evj之间的最终事件相似度得分。系统会筛选出相似度得分最高的前k个事件。对于场景部分,我们计算了相关指标。场景描述与知识图谱中候选场景之间的语义相似度:
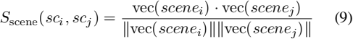
其中,Sscene(sci、scj)表示场景描述sci和scj之间的语义相似度。vec(scenei)和vec(scenej)分别代表这两个场景描述的向量表示。与事件匹配类似,根据最高语义相似度得分选出前k个场景。
最后,通过聚合实体、Top-k事件和Top-k场景构建了一个Cypher3查询,旨在从EES聚合知识图谱中检索相应的上下文节点。这一查询过程在知识图谱中建立了多模态元素与其上下文表示之间的联系。详细的查询流程如附录中的算法??所示,为基于EES节点的上下文检索提供了一个结构化的框架。上下文被定义为更广泛的背景信息,这些信息将多模态图像中的相关实体、事件和场景连接起来:

其中,fcontext是一个函数,用于综合Top-k事件和Top-k场景,以获取适当的上下文。这一过程将图像的各个部分与更广泛的背景信息联系起来,增强了模型在更大框架内解释和推理图像的能力。检索到的上下文节点提供了关键细节,如描述、时间和地点,进一步丰富了多模态的理解。
4.实验
4.1 设置
在我们的实验中,我们设计了三个全面的任务来评估COSINT-Agent的性能:实体。通过EES-Match在EES-KG中实现识别、EES生成和上下文匹配。所有实验均在配备双A800 80GB GPU的环境中进行,确保高效处理大型语言模型(LLMs)和数据集。实验使用Neo4j作为底层知识图谱框架,并采用Cypher(Francis等人,2018)作为查询语言与知识图谱交互。
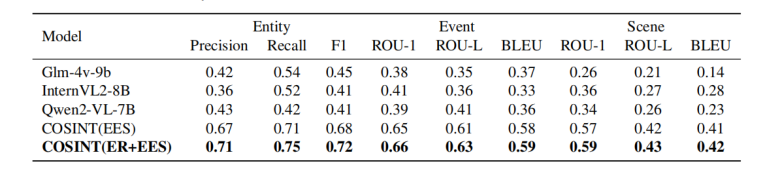
表2.COSINT-MLLM(EES)、COSINT-MLLM(ER+EES)与基线模型在实体识别方面的性能对比。事件生成与场景分析任务。评估指标包括精确度、召回率、F1值、ROUGE-1、ROUGE-L以及BLEU分数。
实体识别实验旨在提升COSINT-MLLM从文本数据中识别实体及其类型的能力,这是操作系统智能任务的基本要求。该模型通过使用包含人物、组织、地点和物体等多样实体的实体(类型)识别数据集进行了微调。微调后,COSINT-MLLM在实体类型识别的准确性、精确度、召回率和F1分数方面与其它主流模型进行了对比。
为了提升COSINT-MLLM对多模态数据的感知和描述能力,EES生成实验专注于从文本和图像中提取EES。该模型使用了多模态EES数据集进行了微调,该数据集包含多模态指令,旨在评估模型对复杂多模态关系的理解。我们根据实体提取的精确度、召回率和F1分数,以及事件和场景描述的BLEU和ROUGE分数,将COSINT-MLLM的输出与其他多语言模型进行了对比。
在EES-KG实验中,通过EES-Match评估了各种大型语言模型(LLM)识别多模态数据上下文的准确性。具体而言,任务是将不同模型生成的EES描述与EES-KG中的相应上下文节点进行匹配。上下文节点代表了多模态数据所描绘的更广泛背景或场景。评估指标包括匹配准确率、Hit@1和Hit@2,这些指标用于评估模型识别正确上下文节点的能力,展示了多模态推理与知识图谱能力的整合。
这些实验共同评估了COSINT-Agent在识别、生成和推理方面的能力。针对OSINT任务的多模态数据,突出了其在将大型语言模型与结构化知识图谱集成方面的适应性和稳健性。
4.2 实体识别
本实验评估了COSINT-MLLM在文本数据中识别实体及其相关类型的能力,与几种参数规模相似的主流大型语言模型(LLM)进行了对比。表1提供了详细的比较,包括每个模型的模态类型、中文支持情况和参数大小,以及精度、召回率和F1分数等性能指标。评估的模型包括纯文本模型,如GLM-4-9b-chat(GLM等人,2024)、Qwen2.5-7B-Instruct(团队,2024)和Meta-Llama-3-8B-Instruct(AI@Meta,2024),以及多模态模型,如GLM-4v-9b(王等人,2023)、InternVL2-8B(陈等人,2024b)和Qwen2-VL-7B-Instruct(王等人,2024a;白等人,2023)。尽管纯文本模型通常对多模态操作性情报任务的适应性有限,但多模态模型在实体识别方面难以达到相当的性能。通过使用实体(类型)识别数据集进行微调,COSINT-MLLM取得了显著的进步,其精度为0.81,召回率为0.79,F1分数为0.79。虽然微调过程使模型相对于纯文本LLM有了显著提升,但与其它大型语言模型相比,该模型在准确识别中文文本中的实体方面表现出显著进步。
4.3 EES生成
如表2所示,COSINT-MLLM(ER+EES)在所有任务和指标上均展现出优于COSINT-MLLM(EES)及其他主流多模态大型语言模型(MLLMs)的持续性改进。在实体识别任务中,COSINT-MLLM(ER+EES)实现了0.71的精确度、0.75的召回率和0.72的F1值,相比之下COSINT-MLLM(EES)的精度(0.67)、召回率(0.71)和F1值(0.68)表明,将实体识别整合到微调过程中能带来额外优势,显著提升模型对实体及其类别的理解能力。在事件生成任务中,COSINT-MLLM(ER+EES)的表现略胜一筹,其ROUGE-1(0.66)、ROUGE-L(0.63)和BLEU(0.59)得分均优于COSINT-MLLM(EES)的ROUGE-1(0.65)、ROUGE-L(0.61)和BLEU(0.58)。同样,在场景分析任务中,COSINT-MLLM(ER+EES)的ROUGE-1(0.59)、ROUGE-L(0.43)和BLEU(0.42)得分也略高于COSINT-MLLM(EES),后者在这些指标上的得分分别为ROUGE-1(0.57)、ROUGE-L(0.42)和BLEU(0.41)。尽管COSINT-MLLM(ER+EES)和COSINT-MLLM(EES)之间的改进是逐步的,但它们突显了结合实体识别和多模态EES细调在提升模型整体性能方面的优势。这两种配置显著优于Qwen2-VL-7B、InternVL2-8B和Glm-4v-9b等基线模型,这些模型在所有指标上的得分都远低于前者。例如,表现最佳的基线模型InternVL2-8B在事件生成任务中的ROUGE-1(0.41)、ROUGE-L(0.36)和BLEU(0.33)得分较低,而在场景分析任务中的ROUGE-1(0.36)、ROUGE-L(0.27)和BLEU(0.28)得分也较低。
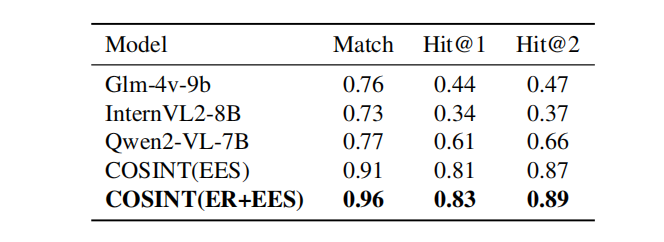
表3.不同模型在上下文匹配中的表现EES匹配。
4.4 基于EES-KG中的EES-Match实现上下文匹配
在EES-KG实验中,我们直接使用了EES生成任务数据集,其中模型生成的数据,包括实体、事件和场景,通过EES-Match模块与知识图谱进行了匹配。我们使用BGE-M3(Chen等人,2024a)进行向量化处理,并利用zh-core-web-sm提取关键动作和事件相关信息。匹配过程通过Hits@1和Hits@2两个指标进行评估,以比较EES-Match与其他基线模型的性能。这种方法能够自动检索相关上下文,增强COSINT应用中的多模态推理能力。下表对比了不同模型通过EES-Match匹配知识图谱中上下文节点的能力。match列显示了成功匹配上下文节点的整体概率,而Hits@1和Hits@2分别表示上下文节点被排在第一和第二位的概率。结果显示,COSINT-MLLM(无论是否包含实体识别)在上下文匹配方面显著优于其他大模型。
表4.EES-Match消融研究结果,比较不同配置(ES、EE、EES)以及事件匹配中动作相似性的影响。
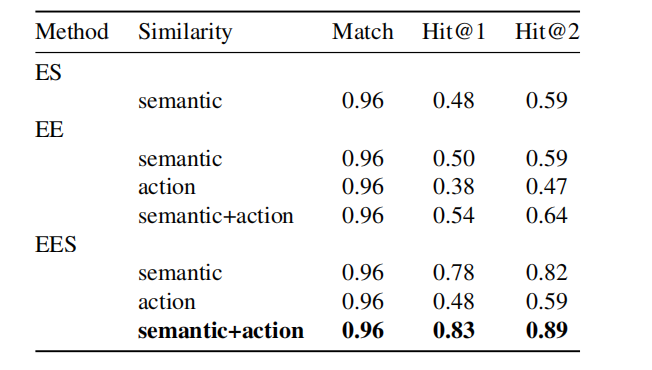
如表3所示,COSINT-MLLM(无论是否包含实体识别和EES微调)在匹配上下文节点方面均优于其他主流模型。特别是,COSINT(ER+EES)的匹配得分为0.96,Hit@1得分为0.83,Hit@2得分为0.89,这突显了所提出的框架在提高多模态上下文检索准确性的优势。这些结果证实了利用EES-Match将多模态推理与基于知识图谱的上下文匹配相结合的可行性和有效性。
4.5 脱脂研究
为了评估EES-Match的有效性,我们进行了消融研究,重点关注了三种配置:实体-场景(ES)、实体-事件(EE)和实体-事件-场景(EES)。此外,对于事件匹配,我们还评估了结合动作相似性和语义相似性的影响。如表4所示,以下观察结果:EES配置在所有指标上均优于ES和EE方法。具体而言,结合语义和动作相似性的EES实现了最高的Hit@1(0.83)和Hit@2(0.89),这表明整合实体、事件和场景信息对于上下文匹配至关重要。将动作相似性加入事件匹配过程后,EE和EES方法的Hit@1和Hit@2得分都有所提升。例如,在EES配置中,同时使用语义和动作相似性使Hit@1从仅语义时的0.78显著提高到结合语义和动作时的0.83,这突显了在多模态上下文检索中详细动作级推理的重要性。这些结果验证了EES-Match的设计选择,并证明了语义和动作相似性的结合,以及实体、事件和场景信息的整合,显著提升了知识图谱内上下文匹配的性能。
5.结论
我们提出了COSINT-Agent,这是一种知识驱动的多模态智能代理,旨在通过创新的EES-Match框架将COSINT-MLLM与EES-KG相结合,以应对OSINT挑战。该代理使用专门的数据集进行了微调,用于实体识别和EES生成,从而在实体识别、EES描述生成以及检索特定上下文的见解方面表现出色。实验结果表明,COSINT-Agent能够有效连接多模态分析与结构化推理,为OSINT任务提供了一个可扩展且精确的解决方案。展望未来,我们预计多语言大模型(MLLMs)在OSINT领域的应用将进一步扩大,未来的重点将是整合实时数据、领域特定知识和高级推理技术,以进一步提升其在复杂情报场景中的适应性和影响力。
参考文献
●AI@Meta. Llama 3模型卡片.2024.网址https://github.com/meta-llama/llama3/ blob/main/MODEL_CARD.md.
●Baek J.、Aji A.和Saffari A.的《知识增强语言模型在零样本知识图谱问答中的应用》一文,发表于2023年计算语言学协会第61届年会。
●白J.、白S.、杨S.、王S.、谭S.、王P.、林J.、周C.和周J. Qwen-vl:一种多功能视觉-语言模型,用于理解、定位、文本阅读及更多功能。arXiv预印本arXiv:2308.12966,2023。
●卡塔赫纳,A.,里默,G.,范·达尔森,T.,沃特金斯,L.,罗宾逊,W. H.,鲁宾,A.侵犯隐私的开源情报威胁评估框架:关键基础设施所有者的安全评估框架。收录于《第10届年度计算与通信研讨会及会议(CCWC)》(2020年),第0494–0499页。IEEE出版社,2020年。
●陈J.、萧S.、张P.、罗K.、连D.和刘Z.,《Bge m3嵌入:通过自知识蒸馏实现多语言、多功能、多粒度文本嵌入》,2024a。
●Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.《扩展视觉基础模型并为通用视觉-语言任务对齐》.收录于《IEEE/CVF计算机视觉与模式识别会议论文集》,第24185–24198页,2024b年.
●德拉瓦拉德,T.、贝尔特朗,P.和图韦诺,V.提取物-利用社交媒体预测未来的犯罪指标。开放数据以检测有组织犯罪威胁:推动未来犯罪的因素,第167-198页,2017年。
●弗朗西斯,N.,格林,A.,瓜利亚尔多,P.,利布金,L.,琳达克,T.,马尔索,V.,普兰蒂科夫,S.,里德伯格,M.,塞尔默,P.,泰勒,A.《Cypher:一种用于属性图的不断演进的查询语言》。收录于《2018年国际数据管理会议论文集》,第1433-1445页,2018年。
●Ghioni,R.,Taddeo,M.,和Floridi,L.开源智能与人工智能:对gelsi文献的系统综述。《AI与社会》,39(4):1827–1842,2024.
●GLM、T.,曾,A.,徐,B.,王,B.,张,C.,尹,D.,罗哈斯,D.,冯,G.,赵,H.,赖,H.,余,H.,王,H.,孙,J.,张,J.,程,J.,桂,J.,唐,J.,张,J.,李,J.,赵,L.,吴,L.,钟,L.,刘,M.,黄,M.,张,P.,郑,Q.,陆,R.,段,S.,张,S.,曹,S.,杨,S.,谭,W. L.,赵,W.,刘,X.,夏,X.,张,X.,顾,X.,吕,X.,刘,X.,刘,X.,杨,X.,宋,X.,张,X.,安,Y.,徐,Y.,牛,Y.,杨,Y.,李,Y.,白,Y.,董,Y.,齐,Z.,王,Z.,杨,Z.,杜,Z.,侯,Z.,和王,Z.。Chatglm:从glm-130b到glm-4的大型语言模型家族,所有工具,2024。
●戈瓦尔丹,D.,克里希纳,G. G. S. H.,查兰,V.,赛,S.V. A.和Chintala,R. R.在网络安全背景下,osint框架面临的关键挑战与局限性。收录于2023年第二届国际边缘计算与应用会议(ICECAA),第236-243页,IEEE出版社,2023年。
●赫尔南德斯,M.,赫尔南德斯,C.,达兹-莱佩兹,D.,加西亚,J. C.和Pinto,R. A.开源情报(osint)作为网络安全行动的支持:在哥伦比亚背景下使用osint及情感分析。《期刊》《科学、技术与社会》第15´卷第2期,2018年。´
●胡,E. J.,沈,Y.,沃利斯,P.,艾伦-朱,Z.,李,Y.,王,S.,王,L.,陈,W. Lora:大型语言模型的低秩适应。arXiv预印本arXiv:2106.09685,2021。
●耶稣,V.,贝恩斯,B.,和张,V.。《分享即关爱:开放、众包网络威胁情报的挑战与前景》。《IEEE工程管理学报》,71卷:6854–6873页,2023年。
●吉,Z.,李,N.,弗里斯克,R.,余,T.,苏,D.,徐,Y.,石井,E.,邦,Y. J.,马多托,A.,冯,P.,《自然语言生成中的幻觉现象调查》。《ACM计算调查》,第55卷第12期:1–38页,2023年。
●李J.、王Y.、李J.和张M.多模态知识图谱的多模态推理。arXiv预印本arXiv:2406.02030,2024。
●莫达尔,D.;莫迪,S.;潘达,S.;辛格,R.;拉奥,G. S.《Kam-cot:知识增强的多模态思维链推理》。收录于《美国人工智能协会会议论文集》第38卷,第18798–18806页,2024年。
●穆塞利-塞尔吉耶、博岑、古列维奇和罗思,《基于多模态翻译的知识图谱表示学习方法》,载于《第七届词汇与计算语义学联合会议论文集》,第225–234页,2018年。
●恩德洛武,L.,姆库赞格韦,N.,德科克,A.,图瓦拉,N.,莫科埃纳,J.,和马蒂马特吉,R.一种基于开源情报(osint)与人工智能(ai)的情境感知工具。收录于2023年IEEE国际数据驱动分析与智能系统会议(ADACIS),第1-6页。IEEE,2023。
●诺胡,M.、护士,J. R.、韦伯,H.和戈德史密斯,M.《网络犯罪调查员也是用户!理解执法部门面临的社技术挑战》。arXiv预印本arXiv:1902.06961,2019。
●潘思,罗乐,王毅,陈晨,王杰,吴曦。统一大型语言模型与知识图谱:路线图。《IEEE知识与数据工程学报》,2024年。
●Riebe,T.、Bumler,J.、Kaufhold,M.-A.和Reuter,C.在网络安全事件响应的态势感知技术背景下探讨价值与价值冲突:基于价值敏感设计的视角。《计算机支持的协同工作》(CSCW)第33卷第2期,205-251页,2024年。
●Sen,P.、Mavadia,S.和Saffari,A.增强知识图谱的语言模型在复杂问题回答中的应用。收录于《第一届自然语言推理与结构化解释研讨会(NLRSE)论文集》,第1-8页,2023年。
●孙瑞、曹曦、赵毅、万军、周科、张飞、王哲和郑可.多模态知识图谱在推荐系统中的应用.收录于《第29届ACM国际信息与知识管理会议论文集》,第1405–1414页,2020年。
●团队Q.Qwen2.5:基础模型的聚会,2024年9月。网址https://qwenlm.github.io/blog/qwen2.5/。
●田一、宋浩、王哲、王虎、胡志、王飞、查瓦拉·N·V和徐鹏.大语言模型的图神经提示方法.收录于《美国人工智能协会会议论文集》第38卷,第19080–19088页,2024年。
●王P、白S、谭S、王S、范Z、白J、陈K、刘X、王J、葛W、范Y、当K、杜M、任X、门R、刘D、周C、周J和林J.Qwen2-vl:提升视觉-语言模型在任意分辨率下的世界感知能力。arXiv预印本arXiv:2409.12191,2024a。
●Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl:提升视觉-语言模型在任意分辨率下对世界的感知能力.arXiv预印本arXiv:2409.12191,2024b.
●王伟、吕静、余伟、洪伟、齐军、王毅、季杰、杨志、赵乐、宋曦、徐健、徐博、李杰、董毅、丁敏和唐继成.Cogvlm:预训练语言模型的视觉专家,2023.
●文Y.王Z.和孙J.《思维导图:知识图谱提示在大型语言模型中激发思想图》。arXiv预印本arXiv:2308.09729,2023年。
●吴一、胡楠、毕思、齐刚、任杰、谢亚和宋伟.《检索-重写答案:一种基于知识图谱的文本增强式语言模型框架》.arXiv预印本arXiv:2309.11206,2023.
●谢瑞、刘振、栾虎、孙敏.图像体现的知识表示学习.收录于《第二十六届国际人工智能联合会议论文集》.国际人工智能联合会议组织,2017.
●赵伟和吴翔.基于多模态知识图谱的实体感知图像描述提升方法.《IEEE多媒体汇刊》,2023年。
●郑一、张然、张杰、叶毅、罗哲、冯子和马一.Llamafactory:统一高效地微调100+语言模型。收录于《第62届计算语言学协会年会论文集》(第3卷:系统演示),泰国曼谷,2024年。计算语言学协会出版。网址http://arxiv.org/abs/2403.13372.
●周B.、邹L.、莫斯塔法维A.、林B.、杨M.、加拉伊贝N.、蔡H.、阿贝丁J.和曼达尔D.,《受害者发现者:利用bert从社交媒体中收集灾害响应中的救援请求》,《计算机、环境与城市系统》第95卷第101824页,2022年。
A.数据集
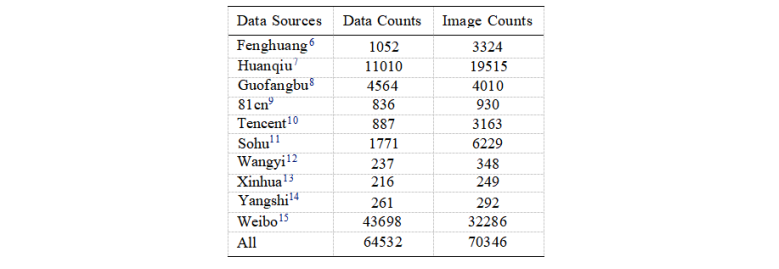
表5.本表概述了收集到的公开情报数据的来源和数量,包括基于文本的数据数量数据条目和相关图像。
6.网址:https://news.ifeng.com/
7.网址:https://mil.huanqiu.com
8.网址:http://www.mod.gov.cn
9.网址:http://www.81.cn/
10.网址:https://news.qq.com
11.网址:https://www.sohu.com
12.网址:https://war.163.com/index.html
13.网址:http://www.news.cn/milpro/index.htm
14.网址:https://military.cctv.com/index.shtml
15.网址:https://weibo.com
根据开源信息的来源及其可信度,收集的数据集分为三种不同的类型:
官方开源信息:这一类别包含来自可信和权威来源的数据,例如政府网站和官方认可的平台(如凤凰、环球、国方播)。这些来源提供的信息高度可信且全面,是构建可靠数据集的理想基础。由于其高可信度和完整性,这类数据主要用于构建实体(类型)识别和多模态EES生成实验的数据集。
非官方开源信息:这一类别包括来自知名新闻平台和商业媒体的数据,如腾讯、搜狐和网易。尽管这类信息总体上是可靠的,但偶尔可能存在偏见或不准确之处。大部分数据用于构建实体(类型)识别实验数据集,而较少部分则被纳入多模态EES生成数据集中。
个人与社交媒体开源信息:这一类别主要包含来自社交媒体平台(如微博)的数据。尽管这些数据量庞大,但由于可能存在偏见、个人观点和未经验证的内容,其可靠性较低。这些数据主要用于构建实体(类型)识别数据集,而少量数据则用于生成多模态EES数据集。
通过利用这一层次结构中的多样化数据源,该数据集确保了信息的平衡呈现,这些信息具有不同程度的可信度。这种结构使得在不同的实验任务中能够有针对性地使用,从而增强了COSINT-Agent在异构开源数据上的多模态推理的稳健性和可靠性。
B. LLM微调损失


图3.左侧图表展示了COSINT-MLLM在使用实体(类型)识别数据集进行微调时的损失曲线,包括原始和平滑后的损失曲线。右侧图表则展示了COSINT-MLLM在使用多模态EES数据集进行微调时的损失曲线,同样显示了原始和平滑后的损失曲线。

