
多端合一,数据统一(PC/WAP/APP/微信)一键管理 适于B2C/B2B/B2B2C等各种商业模式版本的不断优化升级确保功能在最前沿,双热数据备份,实施保障数据安全……
立即咨询什么是中文分词
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。
三大算法
现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
字符匹配
又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
理解法
通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
统计法
词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。
两大技术难点
中文是一种十分复杂的语言,让计算机理解中文语言更是困难。在中文分词过程中,有两大难题一直没有完全突破。
01.
歧义识别
歧义是指同样的一句话,可能有两种或者更多的切分方法。主要的歧义有两种:交集型歧义和组合型歧义
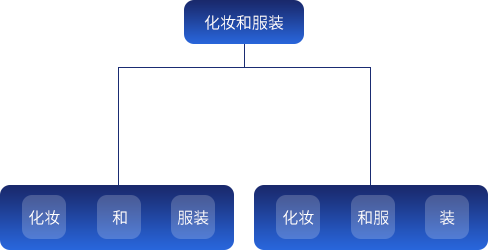
组合型歧义
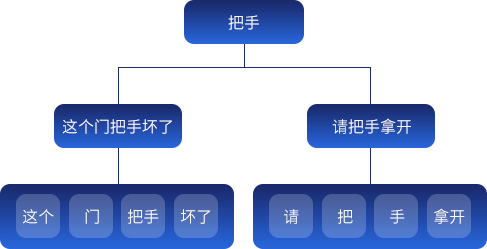
交集型歧义
02.
新词识别
命名实体(人名、地名)、新词,专业术语称为未登录词。也就是那些在分词词典中没有收录,但又确实能称为词的那些词。最典型的是人名,人可以很容易理解。句子“王军虎去广州了”中,“王军虎”是个词,因为是一个人的名字,但要是让计算机去识别就困难了。如果把“王军虎”做为一个词收录到字典中去,全世界有那么多名字,而且每时每刻都有新增的人名,收录这些人名本身就是一项既不划算又巨大的工程。即使这项工作可以完成,还是会存在问题,例如:在句子“王军虎头虎脑的”中,“王军虎”还能不能算词?



© 2005-2023 CNSunRun. All Rights Reserved. 武汉尚软科技有限公司 版权所有 鄂ICP备16017792号-2